Portfolio
Work
A selection of AI products, data systems, and automation I've built at Google and Roblox — RAG assistants, LLM pipelines, research APIs, and the tooling behind trust & safety and transparency. I came from pure humanities and taught myself to code by building; these tools are how I built my way into product management.
All projects are internal tools; details are described at a level appropriate for public sharing.
Career Progression
– present
Leading transparency reporting strategy for 8+ global regulations (EU DSA, UK OSA, NY S895, and more). Building an AI-assisted compliance data model and automated reporting pipeline.
– Oct 2025
Helped stand up the evaluation program for Chrome’s agentic browsing AI in its earliest dogfood phase, working directly with the PM Lead. Drove org-wide AI enablement and regulatory delivery programs.
– Jul 2025
Automated CMA compliance reporting from 60–80 person-hours to <5. Built AI-powered legal review pipelines; designed Sandpiper RAG assistant; won TPgM AI Hackathon.
– Jun 2024
Launched content moderation policies across Gemini, Search, Ads & Play. Developed GenAI tooling for legal ops; built Chrome Extension saving $50k+ in vendor time.
– Apr 2021
Led policy for elections compliance and pandemic business continuity. Built automation reducing manual processing by 30+ hours/week, adopted in 140+ markets globally.
– Sep 2018
Front-line content moderation at scale — 10k+ legal removal decisions across 10+ products. Cut avg. processing time by 93%, from 27 to 2 days, and SLA compliance from 12% to 98%.
No projects match this filter.
Roblox Transparency Reporting & Compliance Data Model
Roblox · 2025–presentA growing wave of regulations — EU DSA, EU TCOR, UK OSA, NY S895, CA AB 587, Brazil ECA, India IT Rules, and others — each require granular, consistently-localized transparency reporting. Roblox’s previous approach was manual and difficult to scale as the regulatory landscape continued to expand.
- Lead transparency reporting strategy and production for 8+ international regulations.
- Wrote a suite of modular, production-grade SQL queries with version control for repeatable, auditable reporting cycles.
- Designing a Product Compliance Unified Data Model and automated reporting pipeline to scale and future-proof the system ahead of external audits.
- Leading AI enablement initiatives to improve team productivity and reduce manual overhead.
- Published Roblox’s most comprehensive EU DSA transparency report to date — the first using the mandatory harmonized reporting format with highly granular, consistently-localized EU data on content moderation, government orders, illegal content, user appeals, and automated systems.
- Building toward full automation of transparency reporting, eliminating manual overhead and improving audit-readiness for an expanding regulatory portfolio.
Roblox Research Data API
Roblox · 2025–presentResearchers studying online platforms — academics, civil society organizations, and platform safety analysts — have had no official, programmatic way to access Roblox’s public data. Without structured access, external research has relied on manual collection or unofficial scraping, limiting the quality and scale of independent scrutiny Roblox could receive on content moderation, platform safety, and policy enforcement. Meanwhile, Roblox had no mechanism to proactively support the research community that informs policymakers and public understanding of major platforms.
- Identifying the opportunity to create Roblox’s first-ever public Research Data API — a capability that has never existed at the company and is not standard practice among major gaming platforms.
- Leading end-to-end product strategy: scoping what public data to expose, designing the API schema and endpoint architecture, and defining data governance, researcher access controls, rate limiting, authentication, and terms of use.
- Driving cross-functional alignment across Engineering, Legal, Policy, and Privacy to design a compliant, sustainable, and scalable access model.
- Positioning the API as a structured complement to Roblox’s existing transparency reporting — extending the company’s public accountability posture beyond periodic reports into queryable, on-demand data access.
- Creates the first official, programmatic pathway for researchers to access Roblox’s public platform data — a major step forward for transparency that the company has never before offered.
- Enables independent scrutiny of platform safety, content moderation effectiveness, and policy enforcement at scale — directly supporting the academic, civil society, and regulatory research community.
- Positions Roblox as a leader in research data access among major gaming and social platforms, ahead of industry norms.
Building Production Queries with AI
Roblox · 2025–presentBuilding production-grade SQL and Python for 10+ regulatory compliance requirements — reports, RFIs, risk assessments, and litigation support — would normally take 3–6 engineering weeks of pure coding per cycle. With a fast-expanding regulatory portfolio and a lean team, that pace was infeasible.
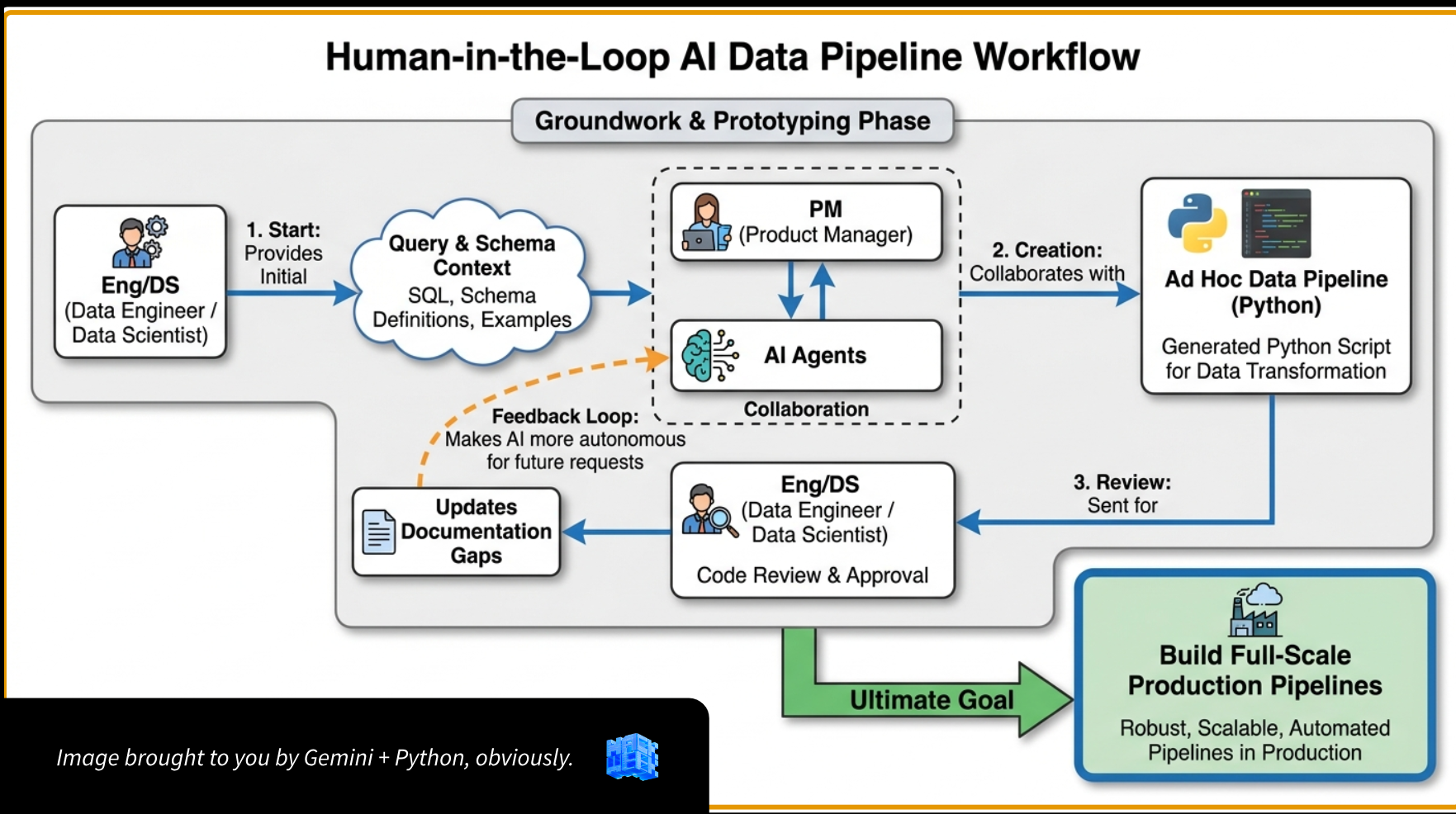
- Operated as PM and first author in a human-in-the-loop AI coding workflow, using Cursor agents to generate production-grade SQL and Python.
- Generated 7,000+ lines of production code across 10+ regulatory requirements, with data engineers and data scientists serving as code reviewers rather than primary coders.
- Designed a structured development pipeline: query and schema context → AI-generated SQL → human code review and approval → iterative refinement → full-scale Python pipelines.
- Compressed the feedback loop between PM and engineering, enabling faster iteration and reducing the bottleneck of cross-functional scheduling.
- 3–6 engineering weeks of coding compressed to hours or days of guided AI work.
- 48M+ tokens of production code generated at a total cost of $77.
- Scaled code production across 10+ regulatory requirements without linear headcount growth.
- Established a replicable human-in-the-loop model: PM authors the logic, engineers review the output.
Sandpiper — Privacy Sandbox AI Knowledge Assistant
Google · 2025The Privacy Sandbox Working Group (900+ engineers, PMs, and compliance staff) was drowning in 12,000+ documents sequestered across restricted repositories. Information retrieval was a serious bottleneck — slowing development, regulatory compliance, and strategy — but the sensitivity of the corpus ruled out general-purpose search tools.
- Sole author of the v1 and v2 design documents; primary driver from conception to working prototype.
- Consulted stakeholders across the org to diagnose pain points, then designed the complete end-to-end system: web frontend, backend on Agent Studio, Gemini 2.5 Pro as the LLM, and a vector database indexed with 12,000+ restricted documents.
- Implemented two operational modes: (1) Expert Q&A with RAG and source citation, grounded in the corpus; and (2) a specialized drafting mode to generate first drafts of D&I Criteria Assessments — a high-frequency compliance workflow — directly from user-provided change descriptions.
- Authored the system prompt, defined technical requirements, access controls, and risk mitigations including hallucination guards and mandatory human review.
- Presented the project at the Privacy Sandbox TPgM AI Hackathon; received a spot bonus from a Senior Director for “unlocking potential impact in terms of time savings and quality of regulatory responses.”
- Won 2nd place in the Google Privacy Sandbox TPgM AI Hackathon.
- Designed to serve 900+ users across the Privacy Sandbox Working Group.
- Significantly reduces time spent on information retrieval and initial compliance document drafting.
- Turns a compliance constraint (controlled document corpus) into a knowledge management advantage.
GenAI Legal Review Automation
Google · 2024–2025The Privacy Sandbox Legal team spent several hours every week manually sifting through bug reports and linked documents to prepare a legal review digest. The process was slow, inconsistent, and bottlenecked compliance oversight for the entire Privacy Sandbox initiative.
- Sole author and developer of the end-to-end automation solution.
- Engaged directly with the Legal team to understand their workflow, decision criteria, and what “good” looks like for each sub-team.
- Designed a three-stage pipeline: SQL (F1) to extract relevant bug data → Python (Colab) to orchestrate → Gemini LLM via TextMiner to process.
- Engineered a series of multi-step prompts performing complex cognitive tasks: summarizing linked documents, identifying key risks against specific CMA regulatory commitments, and classifying the required review type (“Review Required” vs. “FYI Only”) for three Legal sub-teams — Product, Competition, and Privacy.
- Saves several hours of manual work per week for program managers across Privacy Sandbox.
- Provides Legal with a consistent, timely, high-quality digest every cycle — reducing risk of overlooking critical items.
- Accelerated the legal review cycle and improved the overall robustness of compliance oversight.
MT Compliance Reporting Automation
Google · 2024–2025Quarterly Monitoring Trustee (MT) compliance reports — a mandatory deliverable under Google’s legal commitments with the UK Competition and Markets Authority (CMA) — were generated manually. The process took over 60–80 person-hours per quarter, was high-stakes, error-prone, undocumented, and dependent on 5–6 individual single points of failure. There was no auditability and no daily visibility into key metrics.
- Sole author and implementer. Three SWEs who originally scoped the project believed only a software engineer could build it — and were skeptical a TPM would attempt it.
- Designed the end-to-end system architecture: an ETL pipeline pulling from multiple internal data sources (Teamgraph, raw system logs, non-standard imports), with complex data processing, LLM enrichment, and automated report generation.
- Architected a PLX workflow executing a series of SQL scripts to extract, process, and enrich data across three working groups (PSWG, NWG, AWG), with dynamic reporting period calculation and export to Google Sheets.
- Implemented version control and modular query design for maintainability, auditability, and elimination of single points of failure.
- Delivered ahead of schedule, over major international holidays.
- Quarterly report time: >60–80 hrs → <5 hrs (>10× reduction)
- Daily metrics: never generated → <10 min (fully automated)
- Error rate: high (undocumented) → zero (validated)
- Auditability: none → >95% (version controlled)
- Stakeholder confidence: low (anxious) → high (confident)
“That was the smoothest cycle ever.” — Legal
“Quickly and deftly navigate some 11th hour complications to land Q3 deliverables without any issues of non-compliance.” — Senior Director, Google Spot Bonus
PSWG Compliance Enforcement System
Google · 2024A significant compliance gap: employees in the 500+ person Privacy Sandbox org were not members of the mandatory Privacy Sandbox Working Group (PSWG), a foundational requirement under Google’s CMA Commitments. There was no automated mechanism to identify, notify, or track non-compliant individuals.
- Proactively identified the compliance gap — entirely self-initiated; not assigned.
- Designed an automated detection system using SQL to cross-reference employee reporting chains with PSWG group membership data.
- Built an AppsScript notification system to automatically email non-compliant individuals and their managers, with tracking to closure.
- Achieved 100% compliance enforcement for a foundational CMA Commitment across a 500+ person org.
- Closed a significant regulatory risk through a scalable, automated enforcement mechanism — at zero engineering cost.
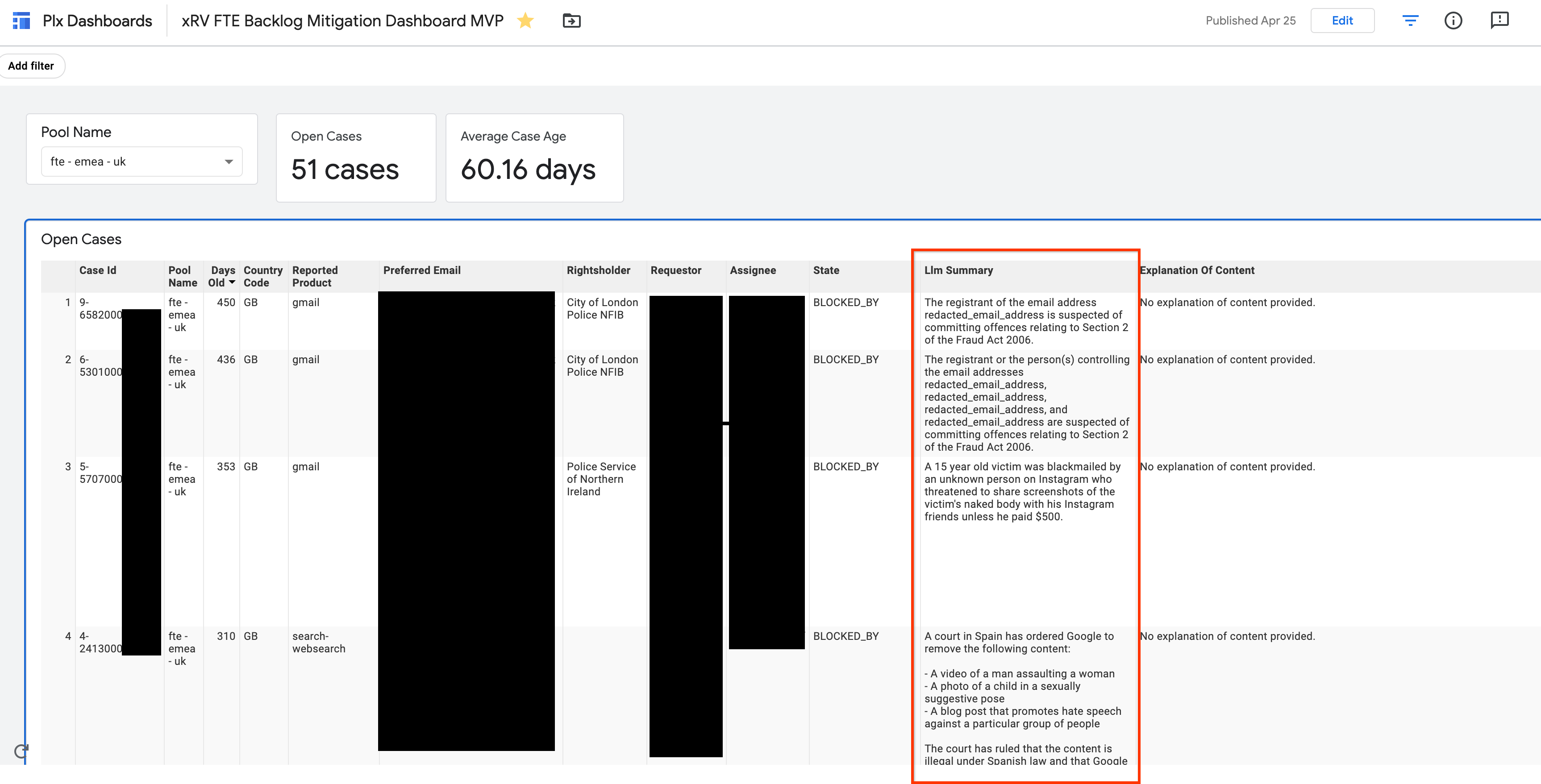
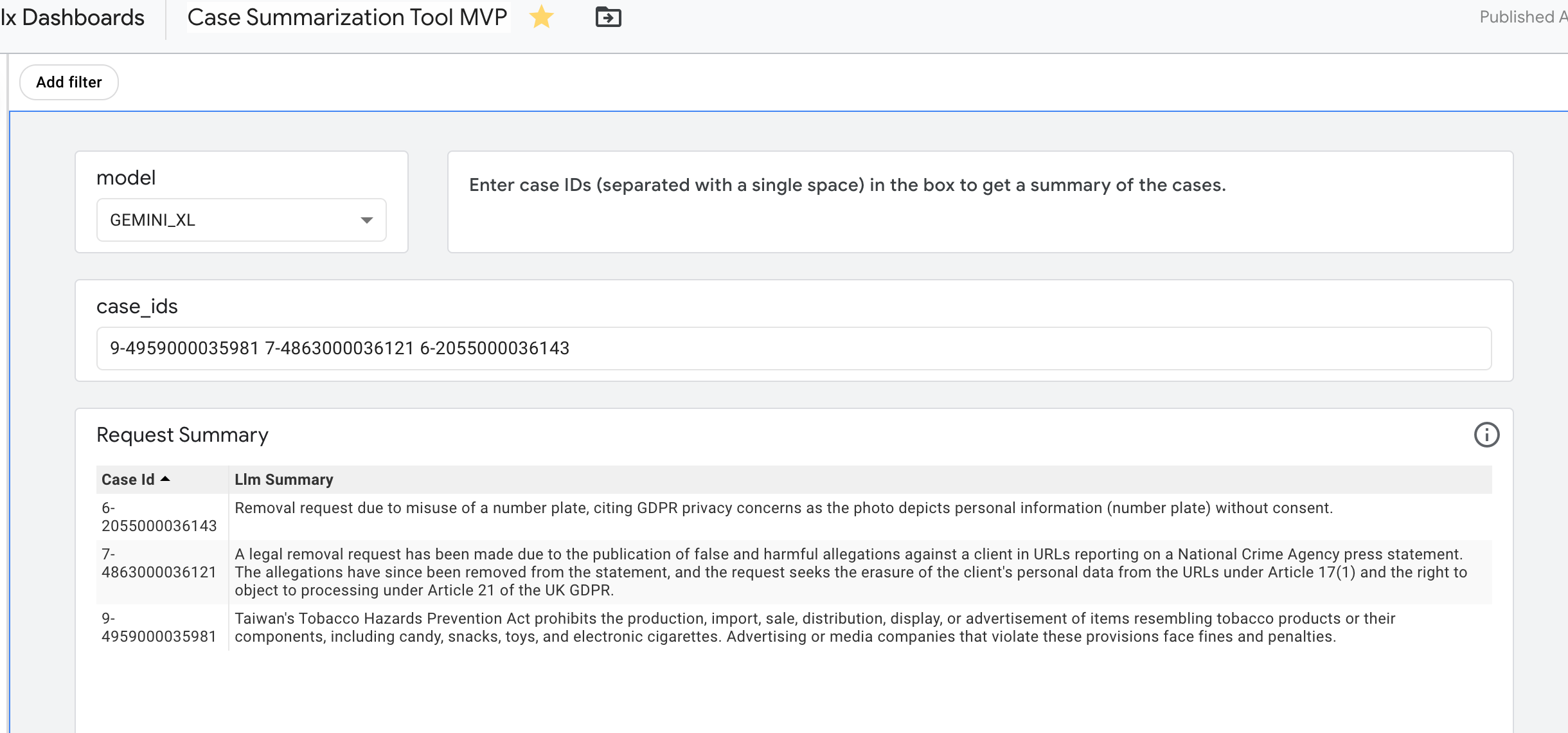
LLM Case Summarization Dashboard
Google · 2023–2024The Legal Content Policy & Standards team needed to quickly understand the essence of thousands of incoming legal removal requests for case management and trend analysis. Manual review at this volume was infeasible. Automatic case summarization was the top-requested feature for their primary management dashboard — but no scalable solution existed.
- Author of the design document, user guide, and lead implementer of the full automated workflow.
- Consulted directly with the LCPS team to define requirements and understand the nuances of how case summaries would be used operationally.
- Designed an innovative pipeline using SQLMiner to perform bulk LLM inference directly within the database environment — avoiding the need to export sensitive case data to an intermediate system and enabling truly industrial-scale operation.
- Engineered a RAG-pattern prompt feeding structured data from case tables into the LLM, producing succinct, accurate, consistently-formatted summaries across every eligible case.
- Surfaced AI-generated summaries directly within the team’s primary PLX management dashboard as an on-demand feature.
- Unlocked significant efficiencies in day-to-day case management for the full LCPS team.
- Enabled faster, more accurate trend analysis across the legal removal case corpus.
- Shifted team focus from low-level individual case review to high-level strategic oversight.
Legal Removal Chrome Extension & Automation
Google · 2021–2023The legal operations team was processing legal removal requests manually — a workflow requiring case-by-case review across multiple internal tools. An 8,400+ case backlog had accumulated, and the ongoing volume (tens of thousands of cases) made manual processing at headcount parity infeasible.
- Built a node.js proof-of-concept automation script to process the immediate backlog of 8,400+ cases, proving the approach worked before investing in a full solution.
- Led development of a production Chrome Extension using browser automation to process legal removal requests at scale — automating the multi-tool workflow that previously required manual interaction.
- Partnered with Engineering to take the approach from proof-of-concept to production-ready tooling.
- Praised by senior PMs for both the speed of delivery and the impact on team capacity.
- $50k+ in vendor time saved through the Chrome Extension automation.
- 700+ working hours saved from the initial node.js backlog automation.
- Processed tens of thousands of cases automatically, enabling the team to scale operations without scaling headcount.
All projects listed are internal tools. Internal system names, go-links, and raw data have been omitted. Metrics cited are consistent with public resume disclosures.